
Within the SAFEXPLAIN project, members of the Research Institues of Sweden (RISE) team have been evaluating and implementing components and architectures for making AI dependable when utilised within safety-critical autonomous systems. To contribute to dependability in Deep Learning (DL) components designed for safety-critical applications, the project strategy focuses on the comprehensive characterization and systematic mitigation of uncertainties inherent in AI systems (that are connected to hazardous situations).
This approach supports compliance with the AI-Functional Safety Management (AI-FSM) development lifecycle and implements the Safety Patterns deployment architecture. Techniques for assuring the dependability of AI components within safety-critical autonomous systems are mainly based on explainable AI (XAI). RISE has contributed to cataloguing and implementing XAI techniques applicable to the different phases of AI-FSM development lifecycle: Data Management, Learning Management, Inference Management.
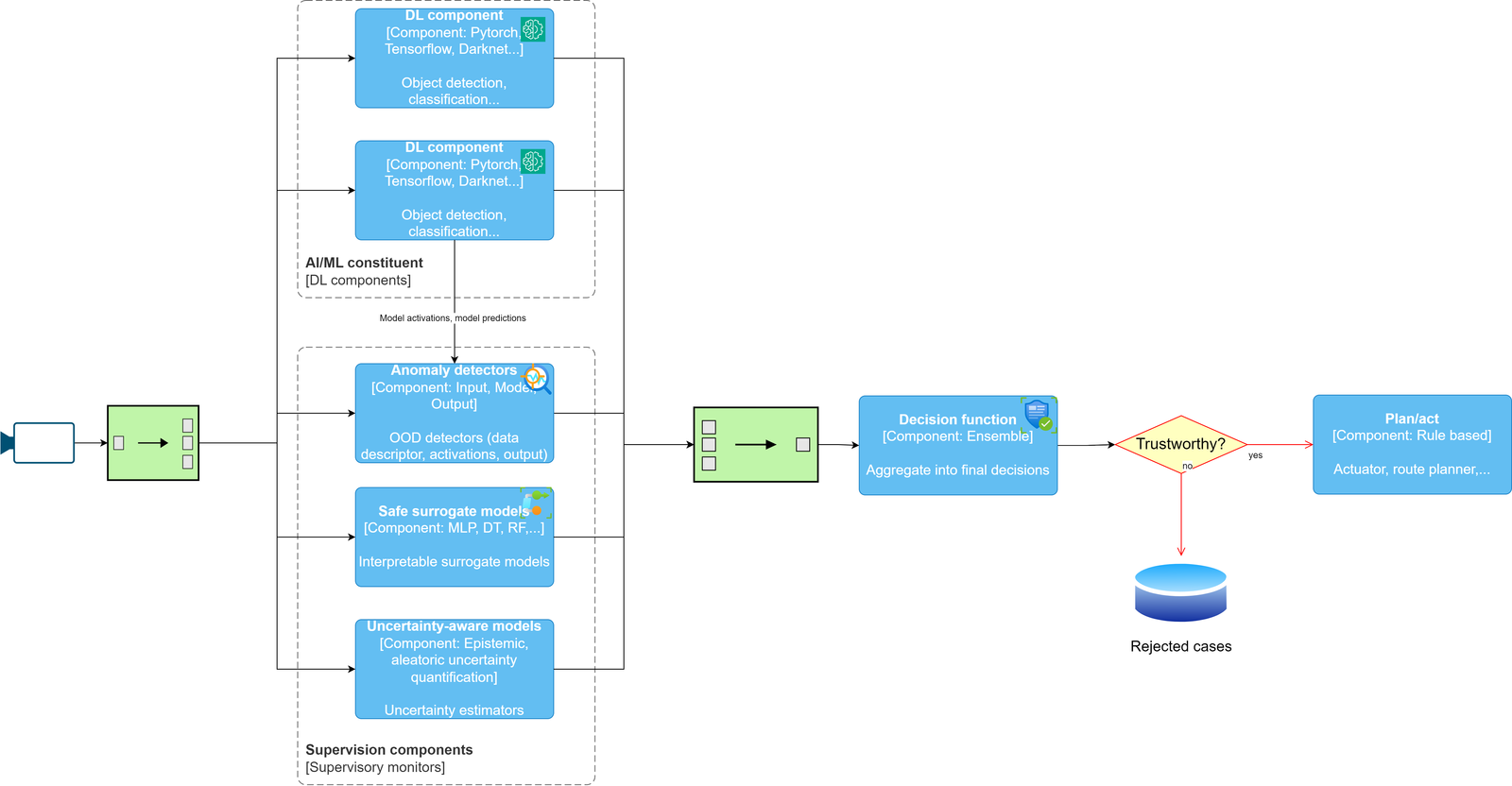
For the deployment phase, much of RISE’s focus has been on the use of XAI techniques with respect to supervision of the AI components. Supervision of the AI components using XAI can be understood in relation to our reference safety architecture of operation and monitoring during deployment (Figure 1).
Figure 1: Reference safety architecture for Operation and Monitoring
In summary, the DL components (top-most blue boxes) consist of diverse redundant deep learning algorithms (specifically Object detector-based algorithms such as versions of YOLO, SSD, or Faster-RCNN). These components are, in turn, evaluated according to three main types of check for out of distribution (OOD) with respect to the models evaluated over AI-FSM:
- Anomaly detectors – these may consist of anomalies affecting the a) input to the model, b) the model inner workings, or c) the output of the model. In relation to a), anomalies may take the form of data corruption, occlusion of objects or unknown environmental conditions; for b), anomalies may consist of non-typical neural activations, abnormal gradient computations; output prediction anomalies consist of unexpected: misclassifications, distributions of object properties (e.g. bounding box size, coordinates), temporal consistency (frame to frame), object size or shape or position. Anomalies may also concern directed adversarial attacks intended to be minimally detectable whilst affecting prediction accuracy.
- Safe surrogate models – interpretable surrogate models are trained to approximate the predictions of the main DL component. Their transparency allows domain and safety experts to verify and certify a safe, albeit less robust, alternative for critical operations. The rationale is that if the “glass-box” surrogates approximate the “black box” deep learning components well, the reasoning process (e.g. in terms of hierarchical feature extraction) guiding the predictions may also be approximately the same. The greater transparency of the surrogate model, then allows for insights into the reasoning process of the deep learning component.
- Uncertainty aware models – these models estimate the uncertainty of the main DL component for a given input/situation, enabling risk quantification for hazardous scenarios and informing safe decision-making. If uncertainty is high for such an input, the risk of an inaccurate prediction that may potentially lead to a hazardous situation may be high.
- Finally, the models’ outputs are subject to a Decision function. This component aggregates predictions from diverse redundant DL components and supervisory monitors to generate an output consisting of a consolidated prediction and a corresponding trustworthiness score calculated as a function of the three safety checks above. Outputs deemed unsafe (rejected) are then stored in a database for use in the development of a future version. Following these stages actions/action plans based on accepted/or not AI predictions are carried out.
We have explored different XAI techniques to handle the above-mentioned supervisor checks and incorporated within a demonstrator platform (NVIDIA AGX Orin) through a SAFEXPLAIN developed Middleware. Our focus has been on applying the Operation and monitoring supervisors to a simplified version of demonstrator based on the space use case, where the safety critical scenario might be precision docking. Anomaly detection has, for example, been investigated using Variational Autoencoders (VAE) – see Figure 3 – designed to detect out-of-distribution features within images that were not known in the original datasets (managed and certified in the data management phase of AI-FSM). Unexpected significance of reconstruction errors or latent distributions that diverge from those seen with the original datasets may be considered anomalous and the respective model’s prediction should not be trusted therefore.
Figure 2 can be an example of an approach to estimate (epistemic) uncertainty using Monte Carlo (MC) dropout. In this example, the variability in model output (regarding location of bounding boxes) is evaluated with respect to a particular input image. Monte Carlo dropout is applied multiple times (500 in this example) and the range in confidence intervals set at 95% is visualized so as to evaluate how certain the model is with respect to a given evaluation.

Figure 2: Epistemic uncertainty quantification for detected object bounding boxes using the SSDLite model as an object detector
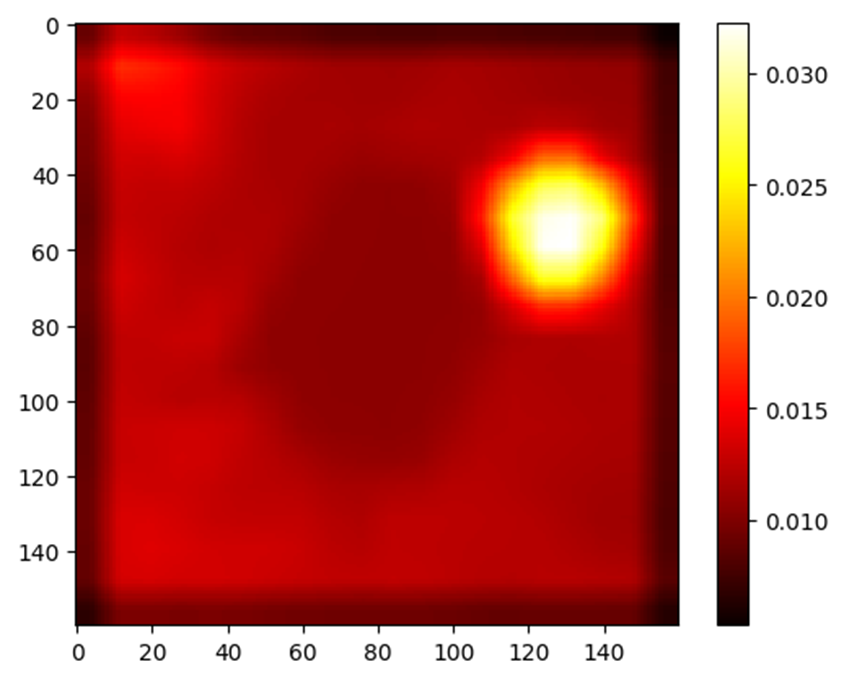
Figure 3: VAE-based OOD detector identifies anomalous areas within the input image