Artificial intelligence, and more specifically, Deep Learning algorithms are used for visual perception classification tasks, like camera-based object detection.
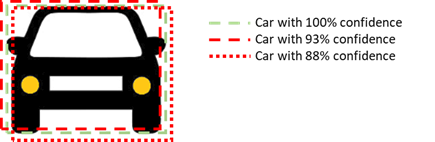
For these tasks to work, they need to identify the right type of object with sufficient confidence, and typically with a square box tightly delimiting the boundaries of the object. However, algorithms using these detections do not need perfect bounding boxes and 100% confidence values.
As long as estimated bounding boxes approximate the real location of the object with sufficient accuracy and confidence levels are above the detection threshold (e.g., confidence above 50%), detections are regarded as semantically correct, despite not being bit-level exact (e.g., the tightest bounding box including the complete object, and 100% detection confidence).
For instance, the picture below shows two examples of semantically correct detections, namely the dashed red and dotted red bounding boxes. In this case, for instance, a collision avoidance algorithm using any such detection would confidently avoid a collision against the detected car.
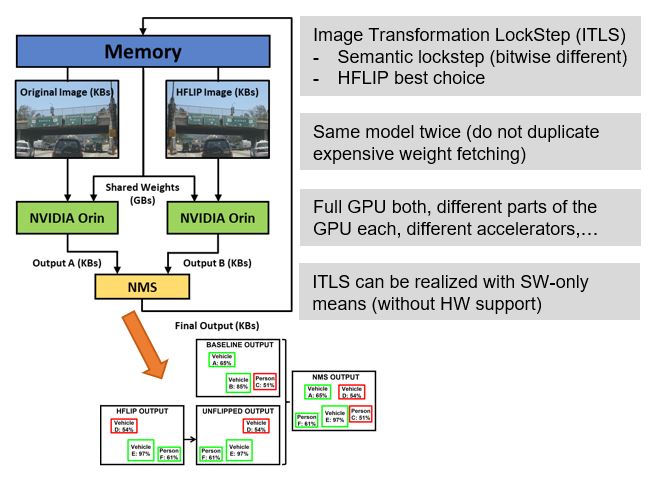
Within the framework of the SAFEXPLAIN project, the Barcelona Supercomputing Center (BSC-CNS) is exploiting AI software’s tolerance of approximate results, specifically in safety-critical applications. By doing so, it is looking for efficient solutions to the mandatory requirement of providing diverse redundant systems that can mitigate by construction single-point failures, specifically with regard to domain-specific functional safety standards (e.g., ISO 26262 in automotive). This requirement is crucial in safety-critical systems like cars, space, and rail, where unreasonable failure risk must be avoided by decreasing error rates, and by detecting and managing remaining errors so that they do not become system failures.
BSC-CNS has devised a diverse redundant scheme for camera-based object detection based on image transformation (e.g., tiny image shifts or rotation, innocuous filters, etc.). This scheme seeks to provide semantically-equivalent outcomes despite using bit-level different images. It does so by operating these images exactly with the same neural network to minimize the cost of fetching data from memory. This is important given the limited memory bandwidth available in inference platforms.
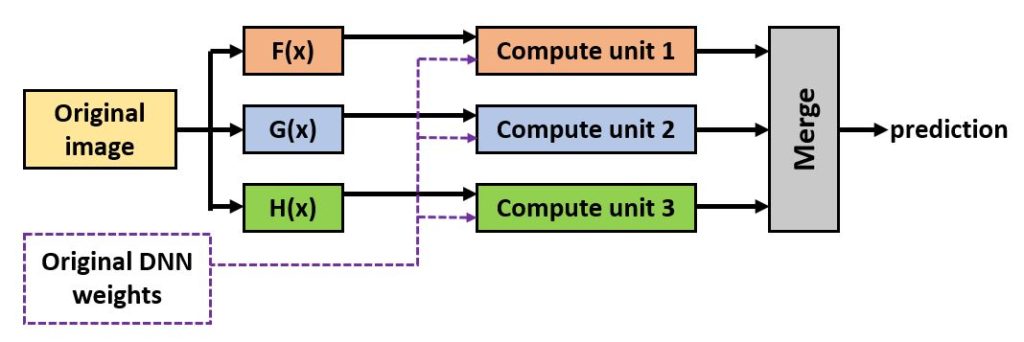
This activity is being run on a NVIDIA Orin platform. So far, the results look promising, and a tool is being built to allow the user to choose their preferred degree of redundancy, the image transformations to use, and the function used to merge redundant outcomes into a single outcome for the end user.