
Exploiting the computational power of complex hardware platforms is opening the door to more extensive and accurate Artificial Intellgence (AI) and Deep Learning (DL) solutions. Performance-eager AI-based solutions are a common enabler of increasingly complex and cutting-edge functionalities. These solutions facilitate decision making processes and autonomous operation in critical embedded domains.
Despite these benefits, the required performance of these AI-based solutions can only be sustained by adopting complex heterogeneous multicore platforms that include a score of ad-hoc hardware accelerator for deep learning and image processing. The exceptional level of performance guaranteed by these types of platforms is typically made possible by enabling highly parallel execution, which is in turn based on the massive sharing of hardware resources among applications.
Hardware resource sharing, however, is exposed to timing interference that arise when contending requests from multiple applications need to be arbitrated. Timing interference may have disruptive effects on the timing behavior of critical applications (Figure 1) and is therefore a major concern for timing verification and, ultimately, functional safety. The interference problem is further compounded by the inherent variability and complexity of AI-based solutions.

Domain-specific standards, like ISO26262 or A(M)C-20-193, advocate for freedom from interference (or interference channels mitigation) as a necessary requirement for timing verification and validation. It is important to note that it is not possible to completely prevent interference without sacrificing performance.
Practical solutions to the timing interference problem focus on: 1) identifying acceptable trade-offs between sustained performance and segregation, 2) exploiting available hardware and software support for resource partitioning, and 3) enforcing carefully-devised Quality of Service configurations, possibly in cooperation with run-time enforcement mechanisms.
The NVIDIA Jetson AGX Orin has been selected as the reference target platform for deploying the three SAFEXPLAIN case studies. These case studies bring representative applications from the automotive, railway, and space domains. The AGX Orin includes a NVIDIA Ampere Architecture GPU with up to 2048 CUDA cores and up to 64 Tensor Cores, up to 12 Arm A78AE CPU cores, 2 next-generation deep learning accelerators (NVDLA), 1 Programmable Vision Accelerator (PVA), and ad-hoc processors to further offload the GPU and CPU.
With up to 275 TOPS of performance, AGX Orin supports the execution of server class AI models at the edge with end-to-end application pipeline acceleration. The Orin enables an exceptional amount of potential resource sharing (Figure 2) that would inevitably jeopardize both performance and predictability if disregarded and left uncontrolled.
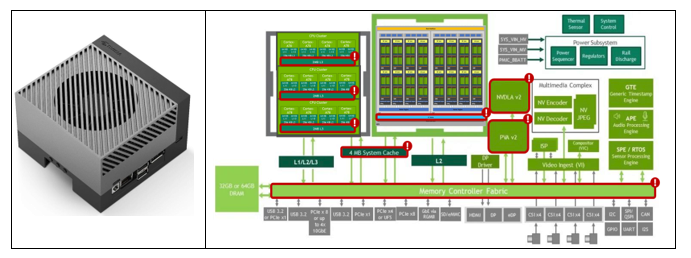
High-level block diagram*, highlighting relevant sources of timing interference.
(Sources: https://developer.nvidia.com/blog/delivering-server-class-performance-at-the-edge-with-nvidia-jetson-orin/
https://developer.nvidia.com/blog/nvidia-jetson-agx-orin-charts-new-path-for-edge-ai-and-robotics/ )
As part of its platform-level support, SAFEXPLAIN investigates effective deployment configurations in the AGX Orin to support performance-efficient solutions for interference mitigation and control, and to ultimately support the certification argument of AI-based systems in the case studies. Deployment configuration will include resource partitioning setups as well as a software architectural pattern encompassing the full SAFEXPLAIN software stack (Figure 3).
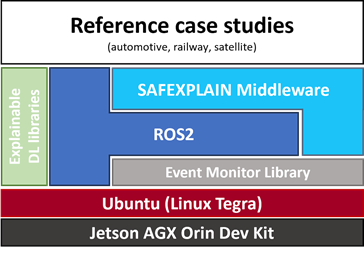
The SAFEXPLAIN software stack will be one of the main catalysers to ensure that SAFEXPLAIN innovations reach the case studies and can be evaluated in representative scnearios. The SAFEXPLAIN stack will enable the implementation and efficient execution of DL.-based applications according to the guidelines coming from the functional stafety part of the project. The effectiveness of the identified deployment configurations for meeting AI performance requirements and timing isolation will be validated using supporting evidence, including empirical data collected, through validated hardware event monitors, over predefined execution scenarios.