
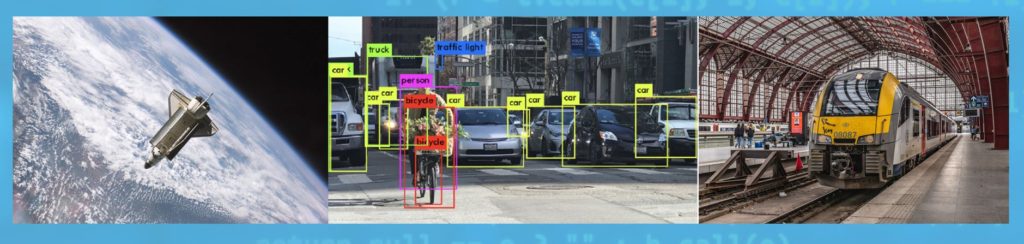
As part of the SAFEXPLAIN project, three case studies were identified to evaluate the SAFEXPLAIN technology to help work toward removing any roadblocks that may prevent the potential future adoption of the technology. Space, automotive and railway cases help evaluate how SAFEXPLAIN can help pave the way toward enabling autonomy features in three artificial intellengence (AI) models. By increasing the explainability and traceability of deep learning (DL) components, and by providing DL-based architectures that can be used in Critical Autonomus AI-based Systems, end-users will be able to develop advanced AI applications in these domains where functional safety is a must.
Using three case studies from different industrial domains ensures that the project considers the needs of multiple fields whose common thread is the potential use of autonomous systems in complex environments, where AI can enable critical and powerful features.
Space, automotive and railway all consider the use case of a vehicle endowed with the ability to move in its environment and perform tasks such as navigation, docking towards a target, identifying general obstacles (pedestrians, animals, objects) and avoiding potential collisions.
Collaborating with project partners
The first activities for the case studies involved synchronizing with the other project tasks to define all mutual needs and requests. The case studies providers defined their software requirements and dependencies for running the algorithms and gave this information to the partner responsible for the SAFEXPLAIN software stack. In turn, the partners working on safety patterns and explainability techniques requested the information they needed to apply their work to the case studies.
To speed up the prototyping phase, the consortium decided to build a test model. This simple DL model is built on resources that are already publicly available. The model exhibits the same core functions of all three case studies but is lighter, less complex and will be readily available for the first tests on integrating the different prototypes that will be soon available in the project, which include the software for running and monitoring the algorithms, explainability applications and more.
Testing and simulating

The partners responsible for the case studies began work on preparing the algorithms and all the environmental tools needed to run and simulate their operational scenarios. Stubbing (simulating) the inputs and outputs of the algorithms is essential to avoid buying costly devices and instruments and recreating complex subsystems and interfaces, which in any case fall out of the scope of the project. With proper software stubbing, the system can tightly mimic the operations in the real scenario.
Generally speaking, the algorithms take as input pictures from one or more cameras, providing information about the environment, and output number, position and distance of obstacles or people detected in the frame, position and pose of the target spacecraft, and any other information required to safely navigate.
This activity embraces different tasks, such as:
- Building datasets that are accurate, realistic and representative, recreating the highest number of situations that can occur during operations. Datasets also need to be coupled with relative ground truths, so that during both training and validation phases the complete information is available.
- Including optics disturbances such as reflections and distortions in the images, and edge cases such as animals or uncommon obstacles on the road, flares on the spacecraft solar arrays, and different conditions of light and weather.
- Implement accessory features which can contribute to the algorithms, such as explicit distance estimation, lanes and rails detection, orthogonality estimation with respect to the target surface
- First execution tests on the board on which the case studies will be run and evaluated.
This phase will provide all the instruments to successfully run the case studies and start applying on them the tools coming from the other WPs, building the project software stack: safety measurements, validation techniques, explainability frameworks and monitoring applications.